AI-Integrated Hardware Comparison: Tensor Processing Units, GPUs, and More

The relentless march of artificial intelligence (AI) has catalyzed remarkable advancements in specialized AI hardware, moving beyond the limitations of traditional CPUs in handling computationally intensive machine learning tasks.
This demand has led to the creation of dedicated AI processors, meticulously designed to expedite specific AI functions.
Leading the charge in AI hardware are Graphics Processing Units (GPUs), initially purposed for graphics rendering, now indispensable in AI for their parallel processing prowess. Complementing them are Tensor Processing Units (TPUs), custom-built by Google, which are optimized for TensorFlow and extensive AI workloads.

Furthermore, Field Programmable Gate Arrays (FPGAs) present reconfigurable chips adept at being programmed for distinct AI tasks, while Application-Specific Integrated Circuits (ASICs) emerge as custom chips tailored for precise AI applications.
These specialized AI chips yield substantial improvements in performance and efficiency over general-purpose processors. They not only accelerate the training of complex AI models but also streamline inference for deployed AI systems.
As AI becomes increasingly integral across industries, specialized AI hardware will be crucial in advancing intelligent systems and applications, thereby defining the trajectory of technological progress.
Tensor Processing Units (TPUs) are specialized AI processors created by Google to boost machine learning workload performance. Introduced in 2016, TPUs are custom chips designed for Google's TensorFlow machine learning framework.
These accelerators excel at the matrix and vector computations inherent in many machine learning algorithms.
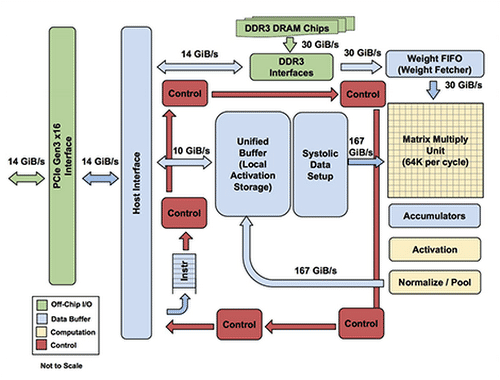
TPUs provide strong performance for AI training and inference. They significantly speed up the training process for large AI models and efficiently manage inference tasks on those models.
A key advantage is their ability to scale. TPU pods link multiple TPU chips, facilitating the training of very large AI models that would be impractical to handle on other types of hardware.
Energy efficiency is another key aspect of the TPU design. These chips are engineered to provide high performance per watt, making them suitable for large-scale AI deployments within data centers.
Google provides access to TPUs through its cloud services, allowing developers to use their capabilities for substantial AI workloads without needing to invest in specialized hardware.
Although TPUs are highly effective for TensorFlow-based tasks, their specialized design may make them less adaptable to other types of computations when compared to more general-purpose accelerators such as GPUs.
For organizations deeply invested in TensorFlow and aiming to expand the possibilities of large-scale machine learning, TPUs offer a robust option within the AI hardware landscape. Understanding the trade-offs between specialization and versatility is key when considering AI acceleration solutions.
Graphics processing units (GPUs) have undergone a significant transformation, evolving from specialized graphics-rendering chips into a cornerstone of AI accelerator hardware.
The parallel processing capabilities that made GPUs suitable for computer graphics are equally effective for the matrix computations and parallel processing required in deep learning and other AI applications.

The primary advantage of GPUs in AI is their architecture. These chips include thousands of specialized cores designed to manage numerous tasks simultaneously. This design is ideally suited to the parallel nature of many AI computations, enabling GPUs to significantly accelerate the training of large neural networks and various AI models compared to traditional CPUs.
Unlike more specialized AI chips, GPUs maintain general-purpose computing capabilities. This adaptability allows them to manage a range of AI and non-AI tasks, making them a versatile choice for organizations with diverse computational requirements.
The broad adoption of GPUs within the AI community has led to extensive software and framework support, further solidifying their role as a primary computing platform for AI model training.
However, GPUs have some limitations for AI workloads. High-performance GPUs can consume considerable power, which might be a concern for large-scale deployments or edge computing scenarios where energy efficiency is important. Additionally, while versatile, GPUs might not achieve the peak performance or efficiency of chips specifically designed for particular AI tasks.
As AI workloads grow in both scale and complexity, GPU manufacturers are developing increasingly powerful and specialized GPUs optimized for AI.
These advancements are expanding what is possible in fields such as deep learning, computer vision, and natural language processing, ensuring that GPUs remain a critical component in the AI hardware landscape for the foreseeable future. The ongoing enhancements in GPU technology underscore their pivotal role in driving AI innovation forward.
Tensor Processing Units (TPUs) and Graphics Processing Units (GPUs) both accelerate AI workloads, but their differing characteristics affect their performance and efficiency across different tasks. Understanding these distinctions is essential for choosing the correct hardware for specific AI applications.

A key difference between TPUs vs GPU is their level of specialization. TPUs are specifically designed for tensor operations prevalent in machine learning, especially those within Google's TensorFlow framework.
This focus allows TPUs to achieve high performance levels for specific AI workloads. Conversely, GPUs offer a more general-purpose architecture capable of handling various parallel computing tasks, including AI.
The computational precision also varies between TPUs and GPUs. TPUs are optimized for the lower precision calculations frequently used in AI inference, potentially improving performance and efficiency for certain workloads. GPUs generally provide greater precision flexibility, allowing developers to select the accuracy level needed for their specific application.
Memory architecture also influences the performance of these accelerators. TPUs incorporate a memory design tailored for AI workloads, which impacts data access patterns and overall performance. GPUs use more conventional memory hierarchies, which might be more familiar to developers but not as optimized for AI-specific tasks.
Regarding scalability, both TPUs and GPUs offer options for managing large AI workloads, but their methods differ. TPU pods enable extensive scaling across multiple chips, tightly integrated with Google's cloud infrastructure. GPUs can also be used in clusters; however, the scaling process may require more tailored configuration, depending on the hardware and software stack being used.
Performance comparisons between TPUs and GPUs can vary widely based on the specific workload, model architecture, and implementation. Generally, TPUs may offer better performance and efficiency for large machine learning tasks optimized for TensorFlow, particularly in cloud environments. GPUs provide more versatility and may perform better for a broader range of AI and non-AI workloads, particularly when using frameworks other than TensorFlow.
The decision to use a TPU vs GPU for a specific AI application relies on factors like workload requirements, the development framework, the deployment environment, and scaling needs.
As these technologies continue to advance, their respective strengths and appropriate use cases may change. Therefore, organizations should regularly reassess their AI hardware strategies.
Evaluating these factors ensures optimal selection and utilization of AI acceleration technologies.
While GPUs and TPUs are central in discussions about AI hardware, Field Programmable Gate Arrays (FPGAs) and Application-Specific Integrated Circuits (ASICs) also play crucial roles in accelerating AI and machine learning workloads.


FPGAs are reconfigurable chips programmable to perform specific tasks. Their flexibility is particularly appealing for AI applications, as they can be optimized for diverse algorithms and workloads.
The advantages of FPGAs in AI include their adaptability to evolving AI techniques, potential for low-latency performance in real-time AI tasks, and their energy efficiency when optimized for specific workloads.
The customizable nature of FPGAs allows developers to create tailored hardware accelerators suited to their AI needs. This is valuable in research or for organizations working with novel AI algorithms not fully supported by standard AI chips.
However, programming FPGAs requires specialized skills, potentially limiting adoption for some organizations.

ASICs represent the highest degree of specialization in AI hardware. These custom chips are designed for specific applications, providing exceptional performance and efficiency for the tasks they are built to handle.
This performance comes at the cost of flexibility; unlike FPGAs, ASICs cannot be reprogrammed, making them less adaptable to algorithm or requirement changes.
ASICs are most effective when maximum performance and efficiency are needed for a stable AI workload.
They are often used in high-volume products where the cost of development can be spread across many units. This includes specialized inference chips for edge devices or custom accelerators for data centers.
Both FPGAs and ASICs offer unique benefits for AI designs and applications. FPGAs balance performance and flexibility, suitable for evolving workloads or edge computing where adaptability is key. ASICs excel where maximum performance and efficiency are needed for a well-defined task, and the workload is stable enough to justify the investment.
As the AI hardware field continues to evolve, FPGAs and ASICs are likely to become increasingly important alongside GPUs and TPUs. They offer a wider array of options for optimizing AI infrastructure to meet performance, efficiency, and flexibility requirements. Recognizing the distinctive roles of FPGAs and ASICs enables a comprehensive approach to AI hardware selection.
As AI workloads increase in prevalence and complexity, AI Processing Units (APUs) and Neural Processing Units (NPUs) are emerging to address the computational demands of AI and machine learning. These processors signify a key evolution in AI hardware, bridging general-purpose computing and specialized AI acceleration.

APUs integrate AI acceleration directly into CPUs, creating a unified architecture that combines CPU cores with dedicated AI units on a single chip. This offers several benefits for AI workloads.
By closely integrating AI processing with traditional CPU functions, APUs can reduce data movement and enhance overall system efficiency for AI tasks. This makes them well-suited for applications needing a combination of general computing and AI acceleration, without needing separate, specialized hardware.
The versatility of APUs makes them appealing for a range of devices. They can enable AI capabilities in systems where dedicated accelerators may be impractical due to cost, power, or space limitations. As AI becomes more integrated into various devices, APUs are likely to play a significant role in bringing AI to mainstream platforms.
Neural Processing Units (NPUs) are specialized AI processors designed to accelerate neural network computations. These chips feature architectures tailored for deep learning and neural network inference. NPUs use highly parallel architectures to accelerate AI workloads, often achieving performance gains over CPUs for specific AI tasks.
A key advantage of NPUs is their potential for low-power operation. Many are designed with energy efficiency in mind, making them suitable for edge computing and mobile devices where power consumption is critical. This allows for the deployment of sophisticated AI in scenarios where traditional high-performance hardware would be impractical.
The development of APUs and NPUs is a key trend in AI processor technology, enabling efficient and capable AI systems across various applications.
It's important to note that the environment around APUs and NPUs is still developing.
Developers may need to adapt their AI models and software to fully use the capabilities of these chips. As the technology matures, increased support for APUs and NPUs in AI frameworks and tools can be expected, accelerating their adoption. Keeping abreast of these developments is crucial for harnessing the full potential of APUs and NPUs in diverse AI applications.
Selecting the right AI hardware requires careful consideration of several factors. The rapidly evolving selection of AI chips offers many options, each with its advantages and disadvantages. The right choice can significantly affect the performance, efficiency, and scalability of AI projects.
One of the main considerations is the specific characteristics of your AI workload. Different AI tasks have different computational demands. For instance, training large models may benefit from the parallel processing of GPUs or the architecture of TPUs.
Conversely, inference on edge devices might be better suited for low-power NPUs or efficient ASICs. Understanding the AI algorithms and the scale of the data is crucial in determining the most suitable hardware.
Performance needs are another key factor. Consider the speed and throughput needed for AI applications. High-performance data center workloads may require TPUs or specialized ASICs, while FPGAs could suit evolving research needs. Benchmarking against different hardware options is vital to ensure adequate performance.
Energy efficiency is increasingly critical, especially for edge and mobile deployments. NPUs and some ASICs offer energy efficiency for AI tasks, which can be essential for battery-powered devices or large deployments where power consumption affects costs.
Scalability is important for organizations with growing AI needs. Evaluate how well the hardware can scale to meet increasing demands. GPU clusters and TPU pods offer scaling approaches, each with advantages based on requirements and infrastructure.
The software ecosystem surrounding the hardware is another vital aspect. Ensure compatibility with preferred AI frameworks. Some hardware, like TPUs, may be optimized for specific frameworks, while others offer general support. Consider the expertise of the development team and the learning curve associated with new platforms.
The deployment environment will also affect hardware choices. Consider whether AI systems will run in data centers, on-premises servers, or edge devices. This affects the hardware used, as well as factors like form, cooling, and integration with existing systems.
Finally, budget and total cost must be weighed. This includes hardware costs and operational expenses like power, cooling, and software licensing. A cost-benefit analysis should consider the hardware's lifespan and its impact on AI project timelines.
Many organizations find that a diverse approach, combining different AI chip types, provides the best solution. For example, GPUs for flexible development and ASICs or NPUs for efficient inference in production environments can be employed.
As the AI hardware landscape evolves, staying informed about emerging technologies and thoroughly benchmarking solutions is crucial for making optimal hardware decisions.
Regular reassessment can help ensure the use of appropriate and cost-effective solutions as AI initiatives grow. This strategic approach to AI hardware selection ensures alignment with evolving needs and technological advancements.
The field of AI chips continues to evolve, with several trends shaping future development. These advancements aim to address current limitations, such as energy consumption and scalability, paving the way for more powerful and efficient systems.
One trend is the increasing specialization of AI chips. As AI workloads diversify, chip designers are creating specialized chips optimized for specific tasks. This trend toward task-specific accelerators is likely to continue, enabling performance for specific workloads.
The push toward edge computing is driving innovation. Developers are focusing on creating power-efficient processors capable of running AI models on devices with limited resources. This is crucial for enabling AI in smartphones and IoT devices, where power consumption is critical.
Neuromorphic computing represents an exciting frontier. Researchers are exploring chip designs inspired by neural networks, aiming to create adaptable hardware. These chips could offer advantages in energy efficiency and the ability to learn in real-time, opening up new possibilities.
In-memory computing is another area of development. New architectures that perform computations directly in memory could reduce data movement, a major bottleneck in current hardware. This approach has the potential to improve energy efficiency and performance, particularly for large networks.
Quantum computing holds potential for accelerating certain algorithms. Researchers are exploring quantum-AI hybrid systems that could leverage quantum computing to solve complex problems. As quantum hardware matures, new AI paradigms that take advantage of quantum effects may emerge.
These advancements in machine learning chips have the potential to enable the next generation of AI breakthroughs. As AI applications continue to grow, hardware innovation will play a crucial role in pushing the boundaries of what's possible.
It's important to note that many of these technologies are still in the early stages. Their practical implementation may take time and will require advancements in manufacturing processes and software ecosystems.
As these trends unfold, they promise to reshape the landscape of AI, enabling capable systems across various applications. Organizations should monitor these developments, as they may offer competitive advantages and open up possibilities for innovation. Keeping abreast of these cutting-edge trends ensures preparedness for the AI-driven future.
In summary, the realm of AI-integrated hardware is characterized by a diverse ecosystem of processing units, each tailored to specific computational demands and application scenarios. From the parallel processing capabilities of GPUs to the specialized tensor operations of TPUs, and the reconfigurable flexibility of FPGAs, the options are vast and varied.
Looking ahead, the strategic selection and integration of AI hardware will be crucial for organizations aiming to leverage AI's transformative potential. As workloads evolve, staying informed about emerging trends, such as neuromorphic computing and in-memory architectures, will provide a competitive edge.
Embracing a holistic approach that considers performance, efficiency, scalability, and compatibility with software ecosystems will pave the way for innovative solutions.
Enterprises should consider piloting hybrid AI systems that combine the strengths of different hardware types. For example, GPUs can be used for initial model development, while ASICs or NPUs can be deployed for efficient inference in production environments.
This agility will allow organizations to adapt to the ever-changing landscape of AI and harness its potential across diverse applications.
Ultimately, the synergistic relationship between AI hardware and software will define the next wave of intelligent systems. By embracing a forward-thinking approach, organizations can unlock new frontiers in AI and drive innovation across industries.

